RAG with SIRI using Verba and Weaviate with a couple lines of code.
I used Verba to create a knowledge base easily and using my voice to fetch appropriate data and open it for me.
We can know use Apple SIRI to do RAG with a Vector Database using Weaviate and Verba to handle RAG
Tech Stack
- Weaviate + Verba - Vector Database + RAG app for easily uploading documents that we want to retrieve from.
- Apple Shortcuts - Trigger + Speech to text
- Ollama - llama3 locally
A spoken request becomes a local retrieval workflow.
Siri captures the query, Shortcuts sends it into Verba, and matching local documents are opened as the answer is spoken back.

I used Weaviate to quickly store documents in my vector database that quickly create vector embeddings that can be easily queried to do RAG with Verba. Essentially I have a knowledge base of my local tax documents that. RAG is natural language processing (NLP) technique that uses large language models (LLMs) to generate more accurate and reliable responses to prompts. Verba uses weaviate under the hood to enable create vector embeddings to return results close to the query and use those files as added context to better the output of the query.
New and improved SIRI you can trigger with Apple Shortcuts:
Tax Document Rag:
After recently watching the movie HER, I wanted to create a tool that can turn SIRI closer to the AI (Samantha) in HER. Our knowledge base has access to files that are important to me like my taxes (for this example they are mocked tax documents as txt files). I wanted every query to open up the file so I can easly open the relevant documents and have some questions answered all done without typing.
Steps to replicate
- Clone Verba Repo: https://github.com/weaviate/Verba + Install pacakges
- Use ollama, creating an .env file:
WEAVIATE_URL_VERBA=http://localhost:8080
OLLAMA_URL=http://localhost:11434
OLLAMA_MODEL=llama3
- Ensure you have a LLM installed from Ollama to run the models locally.
ollama pull llama3
ollama pull mxbai-embed-large:latest
ollama run llama3
Your RAG settings when you run verba start should look like this:
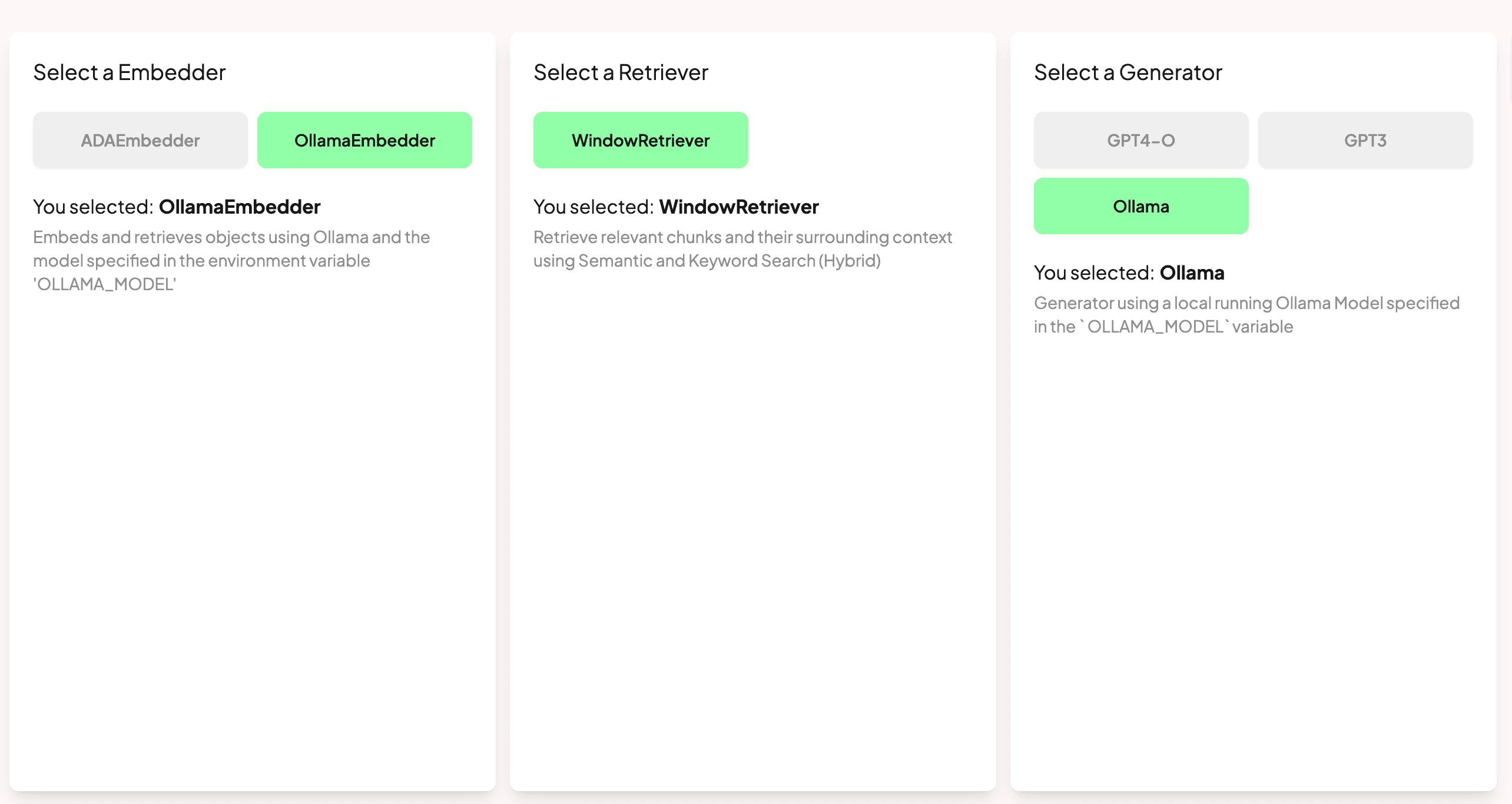
Ensure you select OllamaEmbedder and Ollama saved to run things locally.
- Adjust
api.pyto
Adding to open the retrieved files
def open_urls_in_browser(url):
print('file to open:', f"file:///Users/lorenzejay/workspace/experimental/Verba/data/test_files/tax-mock/{url}")
if(url.startswith('https://')):
return webbrowser.open(url)
webbrowser.open(f"file:///Users/lorenzejay/workspace/experimental/Verba/data/test_files/tax-mock/{url}")
# Receive query and return chunks and query answer
@app.post("/api/query")
async def query(payload: QueryPayload):
msg.good(f"Received query: {payload.query}")
start_time = time.time() # Start timing
retrieved_chunks = []
try:
chunks, context = manager.retrieve_chunks([payload.query])
# THIS WAS CHANGED
for chunk in chunks:
retrieved_chunks.append({
"text": chunk.text,
"doc_name": chunk.doc_name,
"chunk_id": chunk.chunk_id,
"doc_uuid": chunk.doc_uuid,
"doc_type": chunk.doc_type,
"score": chunk.score,
"source_url": chunk.source_url,
})
if float(chunk.score) > 0.74:
open_urls_in_browser(chunk.doc_name)
elapsed_time = round(time.time() - start_time, 2) # Calculate elapsed time
msg.good(f"Succesfully processed query: {payload.query} in {elapsed_time}s")
if len(chunks) == 0:
return JSONResponse(
content={
"chunks": [],
"took": 0,
"context": "",
"error": "No Chunks Available",
}
)
# THIS WAS ADDED
full_text=''
adjusted = GeneratePayload.model_validate_json(json.dumps({
"query": payload.query,
"context": context,
"conversation": [{"type":"system", "content":"Welcome to Verba, your open-source RAG application!"}]
}))
async for chunk in manager.generate_stream_answer(
[adjusted.query], [adjusted.context], adjusted.conversation
):
full_text += chunk["message"]
if chunk["finish_reason"] == "stop":
chunk["full_text"] = full_text
return JSONResponse(
content={
"error": "",
"chunks": retrieved_chunks,
"context": context,
"took": elapsed_time,
"full_text": full_text
}
)
except Exception as e:
msg.warn(f"Query failed: {str(e)}")
return JSONResponse(
content={
"chunks": [],
"took": 0,
"context": "",
"error": f"Something went wrong: {str(e)}",
}
)
This will open up the appropriate files after retrieval
- Upload your documents. This is were the power of Verba comes in. It handles all the complexities of having to create your own RAG app.
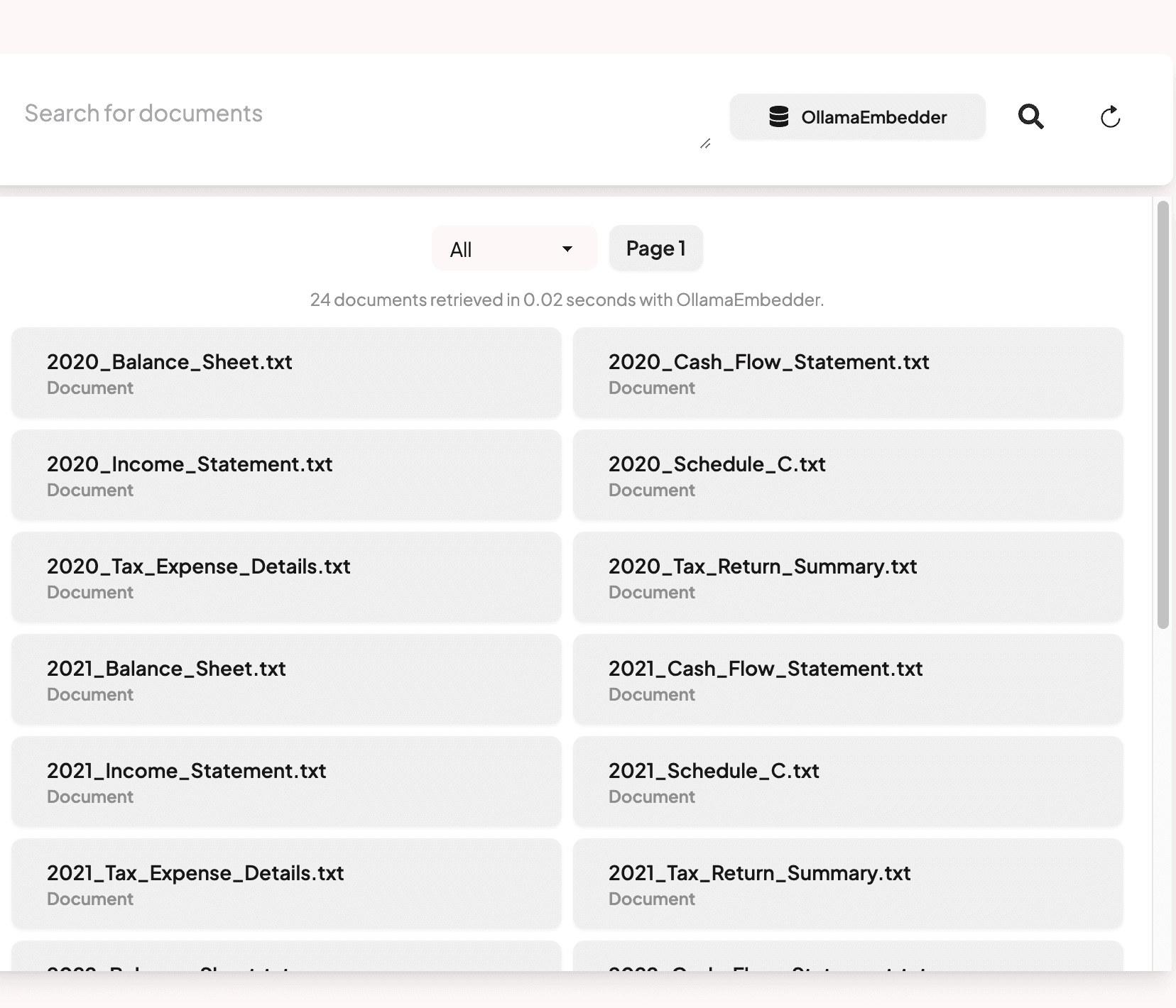
- Now make your shortcut to trigger speech to text:

Our shortcut will hit the query route and pass in any text we say. Then we added some code that will also return the response of the query beyond revieling the retrieved documents. And we have SIRI speak out the response.
You can copy the shortcut here: https://www.icloud.com/shortcuts/290b0c3a721d4fc5bf3fed10a3464b51
You should have something like this at the end:
I'd love to hear how you'd improve this
Send me a DM on twitter and lets chat. https://twitter.com/lorenzejayTech
Source Code: https://github.com/lorenzejay/Verba