Practical Multi Agent RAG using CrewAI, Weaviate, Groq and ExaTool.
Adding rag systems to your agentic workflows can help you build more intelligent systems with more relevant context and data. This guide will show you how to build a practical that uses internal documents to generate a report.
In 2023, Retrieval-Augmented Generation (RAG) applications became a cornerstone for AI-native solutions, offering powerful context retrieval capabilities. Now, in 2024, the rise of agentic applications is revolutionizing automation through AI agents, evolving traditional Robotic Process Automation (RPA) into a more adaptive RPA 2.0 (workflow automation using AI agents). By combining agentic workflows with RAG, we can enhance AI-native applications to not only retrieve relevant context but also automate repetitive tasks that organizations rely on daily. This shift is impacting industries across the board, where tasks like research, document analysis, and report generation are routine and demand a streamlined approach.
What is agentic RAG?
Agentic RAG merges AI agents with RAG systems, enabling agents to retrieve context and relevant details autonomously to accomplish their objectives. Within agentic applications, these agents can dynamically access sources such as internal documents (PDFs, DOCX, Markdown) to efficiently complete tasks. In this practical guide, we'll explore a hands-on approach to creating a team of agents, each with specialized roles, managed by a central "manager agent." Together, we'll build custom tools for our agents while leveraging CrewAI tools to enhance their collaborative capabilities. You can find the full code on Github.
A manager agent routes context into specialist agents.
The workflow starts with a query, fans out to vector retrieval and web research, then flows through CrewAI into a report artifact.
Practical App Overview
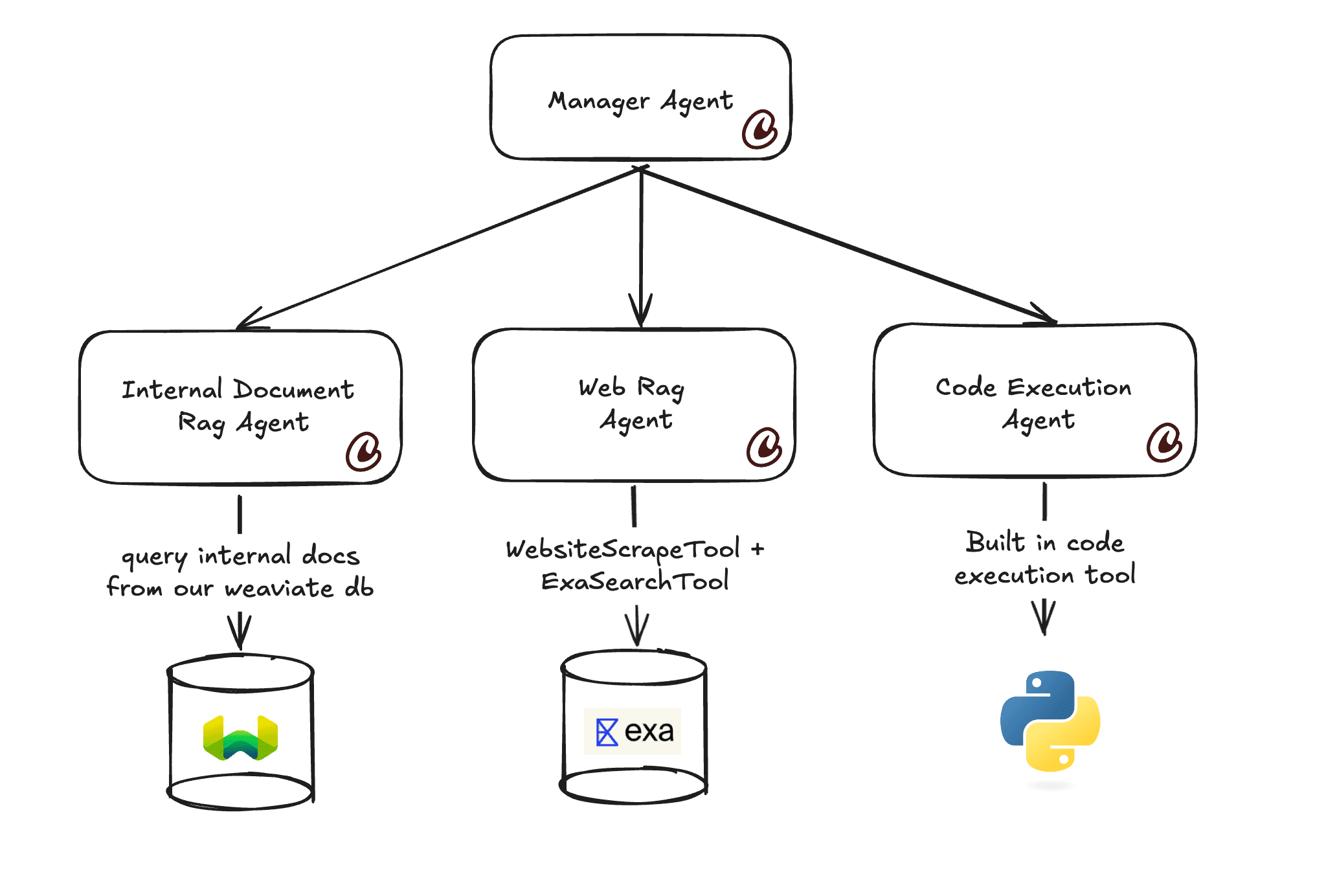
This guide will show you how to build RAG powered CrewAI agents that enables code_interpretation, rag, memory, and building a custom tool. This will be a practical guide that will show you how to build a report using internal documents, competitor research, and graph visualizations.
Output
A report with graph visualizations like this:
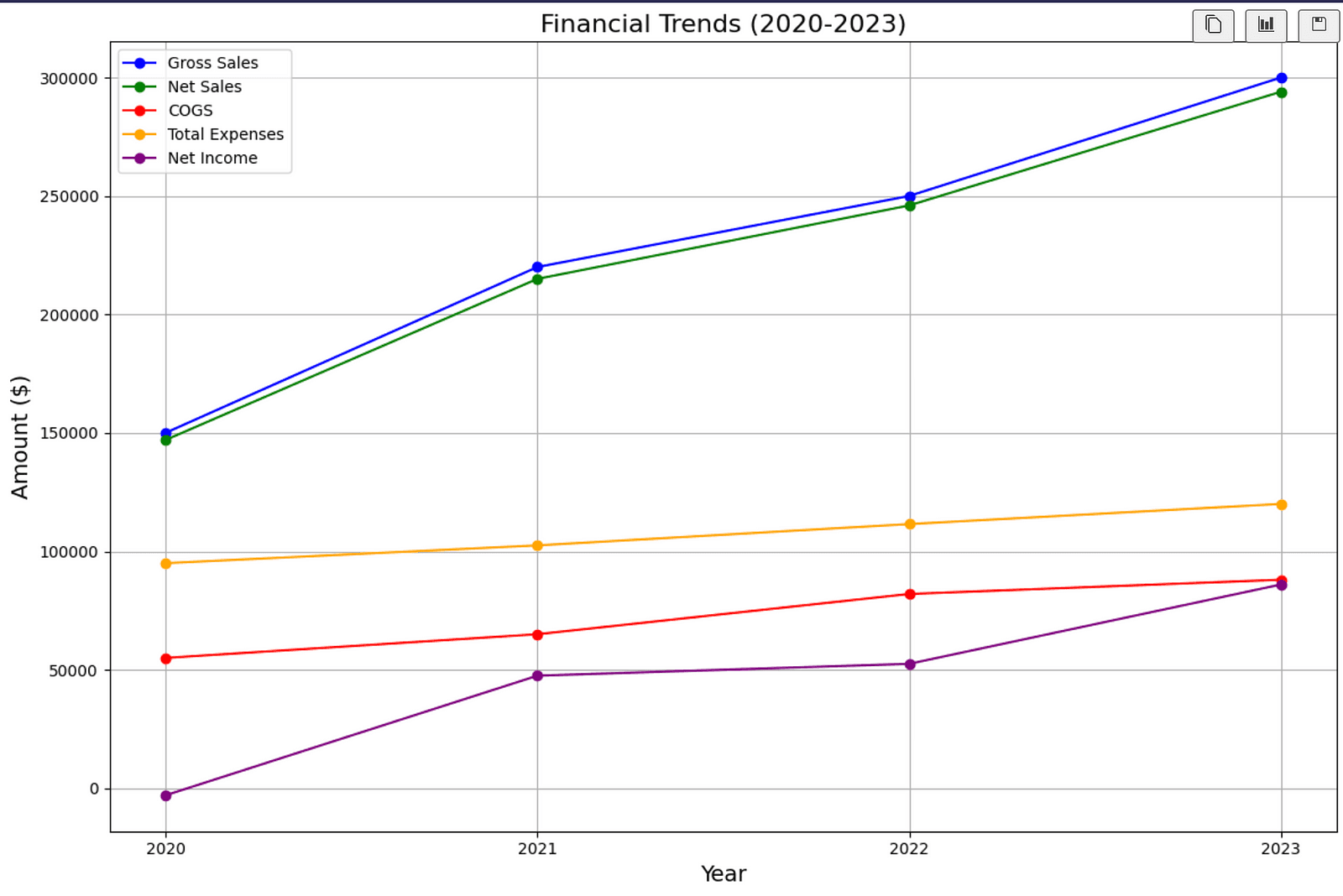
Goal:
Given a query, find relevant docs to generate a report that includes businesses financial data as well as a graph visualizations as a completed report.
Steps
- Fetching relevant docs based on a query.
- Competitor Research
- Generating a writen doc
- Generating graphs for data analysis
Tech Stack
- CrewAI: The leading multi-agent platform
- Weaviate: The AI-native database for a new generation of software
- Groq: Fast AI Inference
- ExaSearchTool: The search engine for AI
- WebsiteSearchTool: Built in web rag tool from crewai_tools
Getting Started
Scaffold a template with the crewai cli
pip install crewai crewai_tool exa-py weaviate-client
crewai create crew agentic-rag
With CrewAI, setting up agents and tasks are super easy using yaml.
document_rag_agent:
role: >
Document RAG Agent
goal: >
Answer questions about the documents in the Weaviate database.
The question is {query}
backstory: >
You are a document retrieval agent that can answer questions about the documents in the Weaviate database.
Documents are internal documents regarding the company
You have tools that allow you to search the information in the Weaviate database.
web_agent:
role: >
Web Agent
goal: >
Answer questions using the web like the EXASearchTool
The question is {query}
backstory: >
You're a web search agent that can answer questions using the web.
your ability to turn complex data into clear and concise reports, making
it easy for others to understand and act on the information you provide.
You have tools that allow you to search the information on the web.
code_execution_agent:
role: >
Code Execution Agent for data visualization
goal: >
You are a senior python developer that can execute code to generate the output
Most of your tasks will be to generate python code to visualze data passed to you.
Execute the code and return the output.
The output file should be valid python code only.
backstory: >
You are a senior python developer that can execute code to generate the output
You have tools that allow you to execute python code.
Execute the code and return the output.
allow_code_execution: true
Defining AI agents should be simple. CrewAI makes it easy. Your agents just need a couple required attributes:
- role
- goal
- backstory
Notice:
code_execution_agent:
role: >
Code Execution Agent for data visualization
goal: >
You are a senior python developer that can execute code to generate the output
Most of your tasks will be to generate python code to visualze data passed to you.
Execute the code and return the output.
The output file should be valid python code only.
backstory: >
You are a senior python developer that can execute code to generate the output
You have tools that allow you to execute python code.
Execute the code and return the output.
allow_code_execution: true
We have an agent, code_execution_agent, that will generate python code in a docker container. All you need is the allow_code_execution flag as true.
tasks.yaml
fetch_tax_docs_task:
description: >
Find the relevant tax documents according to the question: {query}
You can use the WeaviateTool to find the relevant documents.
You need to provide the query and generate an appropriate question for the WeaviateTool.
expected_output: >
The relevant tax documents according to the question and the query.
answer_question_task:
description: >
Find our competitors and their financial data.
Use the WebsiteSearchTool and EXASearchTool to find the relevant information.
expected_output: >
The answer to the question.
The answer should be in markdown format
business_trends_task:
description: >
Generate a report on the latest trends we found in our business. Take our tax data and compare them from year to year: [2020, 2021, 2022, 2023].
You might want to use WeaviateTool to find the relevant tax documents to generate the trends.
expected_output: >
The latest business trends data from all business years.
The report should describe the trends in the data.
output_file: 'outputs/business_trends.md'
graph_visualization_task:
description: >
Generate a graph based on the data generating trends from the business_trends_task.
Use matplotlib to generate the graphs.
You can use the code execution agent to execute the code and generate the output.
The output file should be a python file and not markdown.
expected_output: >
The graph as a png file.
The output file should be a python file and not markdown.
output_file: 'outputs/visualize.ipynb'
Define your workflow. What tasks do you want executed. This can be clear.
main.py
def run():
"""
Run the crew.
"""
inputs = {"query": "What was the year with the highest total expenses?"}
result = AgenticRagCrew().crew().kickoff(inputs=inputs)
if isinstance(result, str) and result.startswith("```python"):
code = result[9:].strip()
if code.endswith("```"):
code = code[:-3].strip()
with open("outputs/visualize.ipynb", "w") as f:
f.write(code)
Creating a Custom Tool
Creating the WeaviateTool
import json
import weaviate
from crewai_tools import BaseTool
from pydantic import BaseModel, Field
from typing import Type, Optional, Any
from weaviate.classes.config import Configure
class WeaviateToolSchema(BaseModel):
"""Input for WeaviateTool."""
query: str = Field(
...,
description="The query to search retrieve relevant information from the Weaviate database. Pass only the query, not the question.",
)
class WeaviateTool(BaseTool):
"""Tool to search the Weaviate database"""
name: str = "WeaviateTool"
description: str = "A tool to search the Weaviate database for relevant information on internal documents"
args_schema: Type[BaseModel] = WeaviateToolSchema
query: Optional[str] = None
def _run(self, query: str) -> str:
"""Search the Weaviate database
Args:
query (str): The query to search retrieve relevant information from the Weaviate database. Pass only the query as a string, not the question.
Returns:
str: The result of the search query
"""
client = weaviate.connect_to_local()
internal_docs = client.collections.get("tax_docs")
if not internal_docs:
internal_docs = client.collections.create(
name="tax_docs",
vectorizer_config=Configure.Vectorizer.text2vec_ollama( # Configure the Ollama embedding integration
api_endpoint="http://host.docker.internal:11434", # Allow Weaviate from within a Docker container to contact your Ollama instance
model="nomic-embed-text", # The model to use
),
generative_config=Configure.Generative.ollama(
model="llama3.2:1b",
api_endpoint="http://host.docker.internal:11434",
),
)
response = internal_docs.query.near_text(
query=query,
limit=3,
)
json_response = ""
for obj in response.objects:
json_response += json.dumps(obj.properties, indent=2)
client.close()
return json_response
Setup for WeaviateDB Added some business finanical data inside directory called /internal_docs
docker-compose.yml
services:
weaviate:
command:
- --host
- 0.0.0.0
- --port
- '8080'
- --scheme
- http
image: cr.weaviate.io/semitechnologies/weaviate:1.27.2
ports:
- 8080:8080
- 50051:50051
volumes:
- weaviate_data:/var/lib/weaviate
restart: on-failure:0
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
ENABLE_API_BASED_MODULES: 'true'
ENABLE_MODULES: 'text2vec-ollama,generative-ollama'
CLUSTER_HOSTNAME: 'node1'
volumes:
weaviate_data:
Preloading docs to WeaviateDB
import os
import weaviate
import json
from weaviate.classes.config import Configure
client = weaviate.connect_to_local()
print(client.is_ready())
internal_docs = client.collections.get("tax_docs")
if not internal_docs:
internal_docs = client.collections.create(
name="tax_docs",
vectorizer_config=Configure.Vectorizer.text2vec_ollama( # Configure the Ollama embedding integration
api_endpoint="http://host.docker.internal:11434", # Allow Weaviate from within a Docker container to contact your Ollama instance
model="nomic-embed-text", # The model to use
),
generative_config=Configure.Generative.ollama(
model="llama3.2:1b",
api_endpoint="http://host.docker.internal:11434",
),
)
docs_dir = os.path.join(
os.path.dirname(os.path.dirname(os.path.dirname(__file__))), "internal_docs"
)
markdown_files = [f for f in os.listdir(docs_dir) if f.endswith(".md")]
with internal_docs.batch.dynamic() as batch:
for filename in markdown_files:
with open(os.path.join(docs_dir, filename), "r") as f:
content = f.read()
batch.add_object(
{
"content": content,
"class_name": filename.split(".")[0],
}
)
print(f"Added {filename.split('.')[0]} to Weaviate")
Examples Document
## Year: 2020
## Income Statement
Gross Sales: $150,000
Returns & Allowances: $3,000
Net Sales: $147,000
## Cost of Goods Sold
Beginning Inventory: $10,000
Purchases: $60,000
Ending Inventory: $15,000
COGS: $55,000
## Expenses
Rent: $30,000
Utilities: $6,000
Salaries & Wages: $50,000
Marketing & Advertising: $4,000
Miscellaneous (Supplies, Insurance): $5,000
Total Expenses: $95,000
## Net Income (Loss)
Gross Profit: $92,000
Net Income (before taxes): $(3,000) (Loss)
## Balance Sheet (End of Year)
### Assets
Cash: $5,000
Inventory: $15,000
Equipment: $25,000
### Liabilities
Accounts Payable: $8,000
### Owner's Equity
Owner's Equity: $37,000
I have a couple years worth for this data in but add the documents you want. We will generate the embeddings with ollama (great for sensitive data)
crew.py
import os
from crewai import Agent, Crew, Process, Task, LLM
from crewai.project import CrewBase, agent, crew, task
from agentic_rag.tools.weaviate_tool import WeaviateTool
from crewai_tools import EXASearchTool
from dotenv import load_dotenv
load_dotenv()
@CrewBase
class AgenticRagCrew:
"""AgenticRag crew"""
llm = LLM(model="groq/llama-3.1-70b-versatile", api_key=os.getenv("GROQ_API_KEY"))
@agent
def document_rag_agent(self) -> Agent:
return Agent(
config=self.agents_config["document_rag_agent"],
tools=[WeaviateTool()],
verbose=True,
llm=self.llm,
)
@agent
def web_agent(self) -> Agent:
return Agent(
config=self.agents_config["web_agent"],
tools=[EXASearchTool()],
verbose=True,
llm=self.llm,
)
@agent
def code_execution_agent(self) -> Agent:
return Agent(
config=self.agents_config["code_execution_agent"],
verbose=True,
llm=self.llm,
)
@task
def fetch_tax_docs_task(self) -> Task:
return Task(
config=self.tasks_config["fetch_tax_docs_task"],
)
@task
def answer_question_task(self) -> Task:
return Task(
config=self.tasks_config["answer_question_task"], output_file="report.md"
)
@task
def business_trends_task(self) -> Task:
return Task(config=self.tasks_config["business_trends_task"])
@task
def graph_visualization_task(self) -> Task:
return Task(config=self.tasks_config["graph_visualization_task"])
@crew
def crew(self) -> Crew:
"""Creates the AgenticRag crew"""
return Crew(
agents=self.agents, # Automatically created by the @agent decorator
tasks=self.tasks, # Automatically created by the @task decorator
process=Process.hierarchical,
verbose=True,
manager_llm="openai/gpt-4o",
)
Hierarchical Process
Enables full agency when it comes to our AI agents making decisions. Our tasks involve:
- Fetching relevant docs based on a query.
- Competitor Research
- Generating a writen doc
- Generating graphs for data analysis
Based on these tasks, our manager agent has access to delegating to our specialized agents for:
- document_rag_agent
- web_agent
- code_execution_agent
Execute
Running our crew is easy. Just do crewai run
crewai run
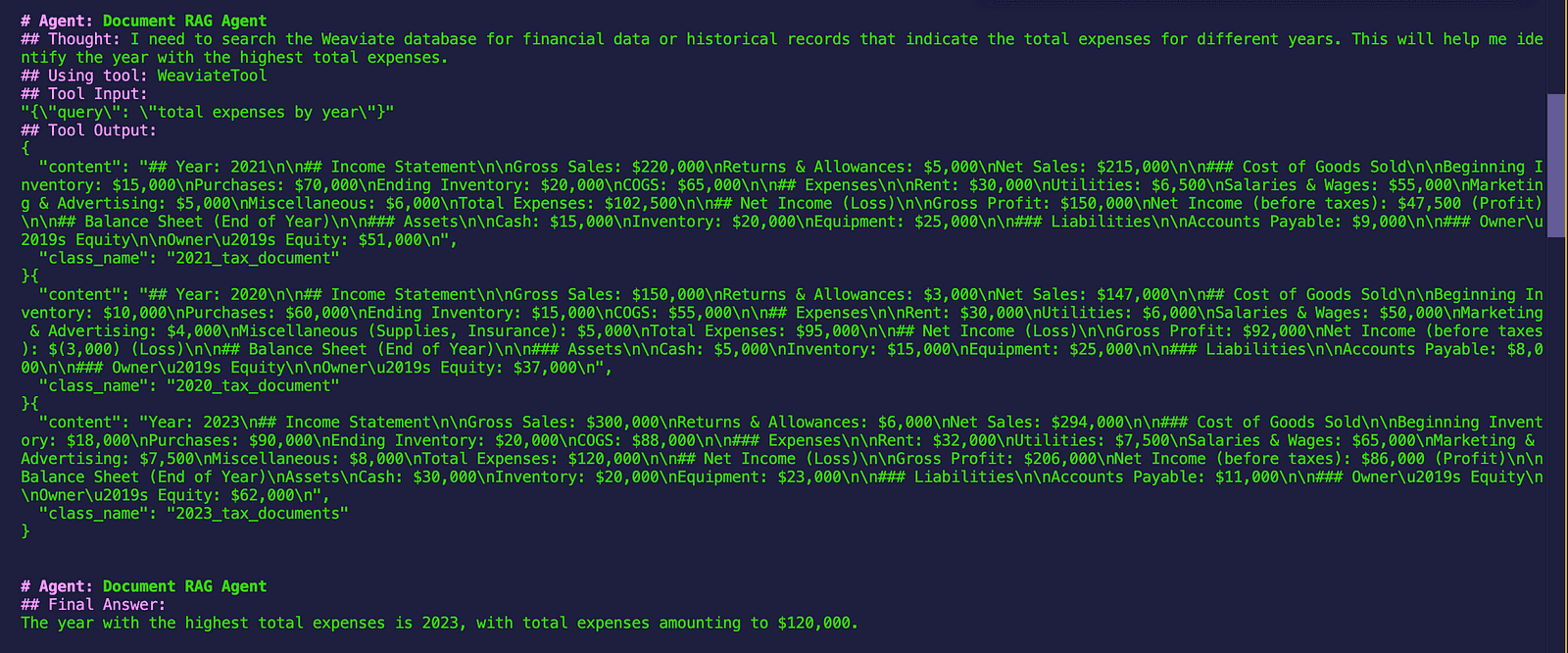
Output
Next Steps
Deploy to production at https://app.crewai.com. You can start for free.
Conclusion
This practical guide showed you how do build an agentic automation leveraging rag capabilities to provide your agents with relevant information to succeed. While you're exploring use cases, think about something you do everyday repetitively. I challenge you to build an automation for it.
Good luck. If you have any questions, you can find me on twitter/x.